FLAME GPU 2: GPU-Accelerated Agent-Based Modeling for Large-Scale Social Simulations
Agent-based models (ABMs) of social systems — opinion dynamics, market adoption cascades, organizational behavior, epidemic spread — routinely require millions of interacting agents to produce statistically meaningful results. Traditional CPU-bound frameworks hit a wall well before that scale. FLAME GPU 2 (Flexible Large-scale Agent Modelling Environment for the GPU) is an open-source C++/CUDA framework developed at the University of Sheffield that moves the entire agent execution pipeline onto the GPU, delivering one to two orders of magnitude more throughput than equivalent CPU implementations for population-scale social simulations.
Why GPU Acceleration Changes the ABM Calculus
Modern GPUs contain thousands of CUDA cores designed for massively parallel workloads. An ABM with one million homogeneous agents executing the same behavioral rule set maps almost perfectly onto this architecture: each agent becomes a GPU thread, and inter-agent communication is handled through optimized spatial or message-passing data structures that live in GPU memory. FLAME GPU 2 exploits this by:
- Eliminating host-device data transfers during the simulation loop — agent state arrays remain on the GPU throughout a run.
- Providing a CUDA-native message communication layer with built-in spatial partitioning (grid-based and brute-force modes) so agents can efficiently query neighbors without CPU intervention.
- Exposing a modern C++ API (C++17) that lets modelers write agent functions as ordinary lambdas or free functions, which the framework JIT-compiles into CUDA kernels at runtime via NVRTC.
For social-system modelers, this means a Schelling segregation model with 2 million agents, or a network-based opinion diffusion model with 500,000 nodes and dynamic rewiring, can complete a full parameter sweep in minutes rather than hours.

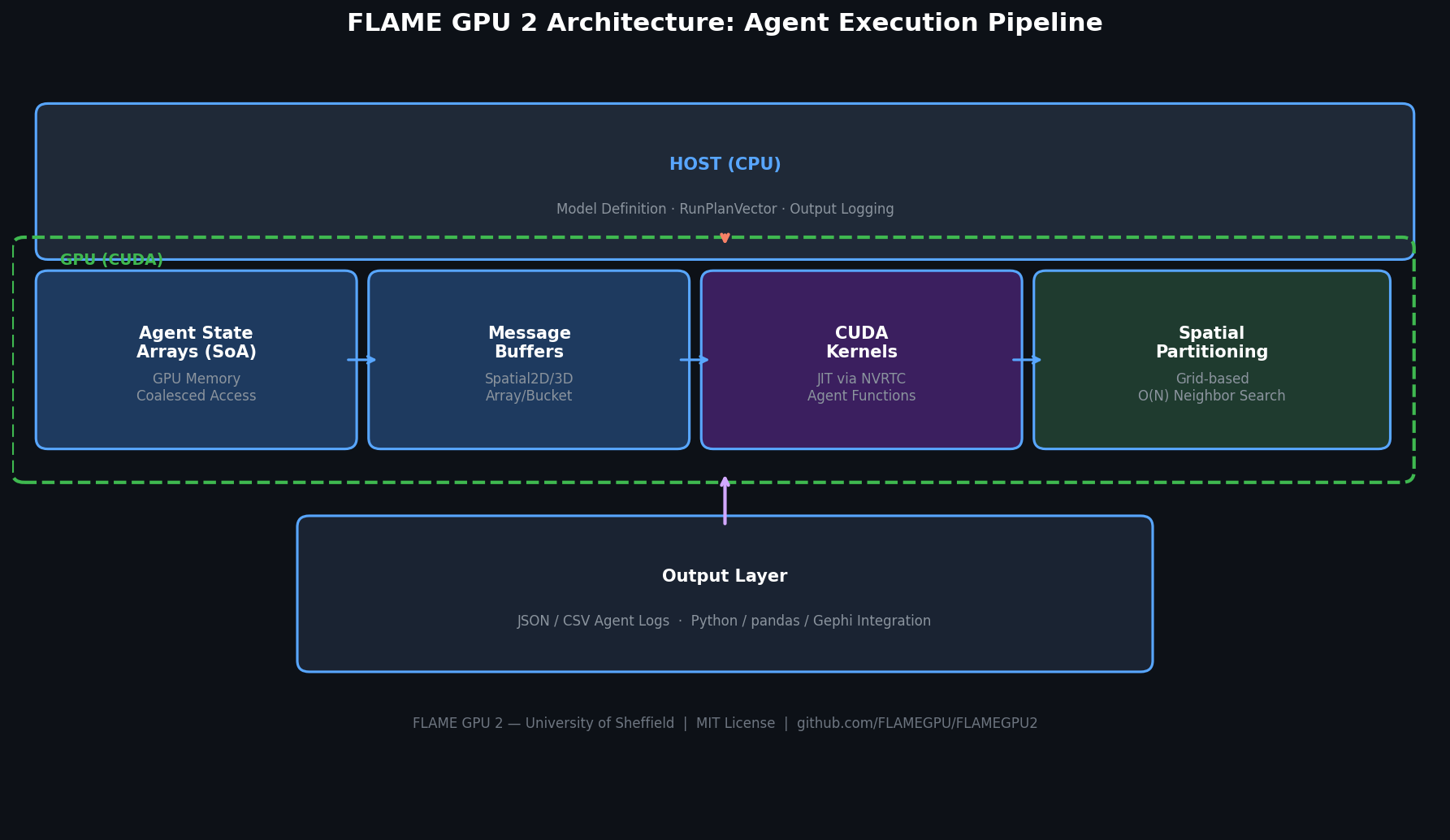
Core Architecture
Agent Populations and State Variables
FLAME GPU 2 organizes agents into typed populations. Each population has a fixed schema of state variables (integers, floats, vectors) stored in structure-of-arrays (SoA) layout for coalesced GPU memory access. Defining a population in C++ looks like:
flamegpu::ModelDescription model("OpinionDiffusion");
flamegpu::AgentDescription& agent = model.newAgent("Citizen");
agent.newVariable<float>("opinion"); // continuous opinion in [0,1]
agent.newVariable<int>("stubbornness"); // resistance to influence
agent.newVariable<flamegpu::id_t>("network_id");Message Communication
The framework's message layer is the key to scalable inter-agent interaction. For network-based social models, the MessageArray or MessageBucket types allow agents to broadcast their state to a logical neighborhood without any CPU-side loop:
// Agent function: broadcast opinion to network neighbors
FLAMEGPU_AGENT_FUNCTION(broadcast_opinion, flamegpu::MessageNone, flamegpu::MessageArray) {
FLAMEGPU->message_out.setVariable<float>("opinion", FLAMEGPU->getVariable<float>("opinion"));
FLAMEGPU->message_out.setIndex(FLAMEGPU->getVariable<flamegpu::id_t>("network_id"));
return flamegpu::ALIVE;
}A second agent function then reads incoming messages and updates the agent's opinion according to a bounded-confidence or DeGroot averaging rule — all executing in parallel across the entire population.
Spatial Social Models
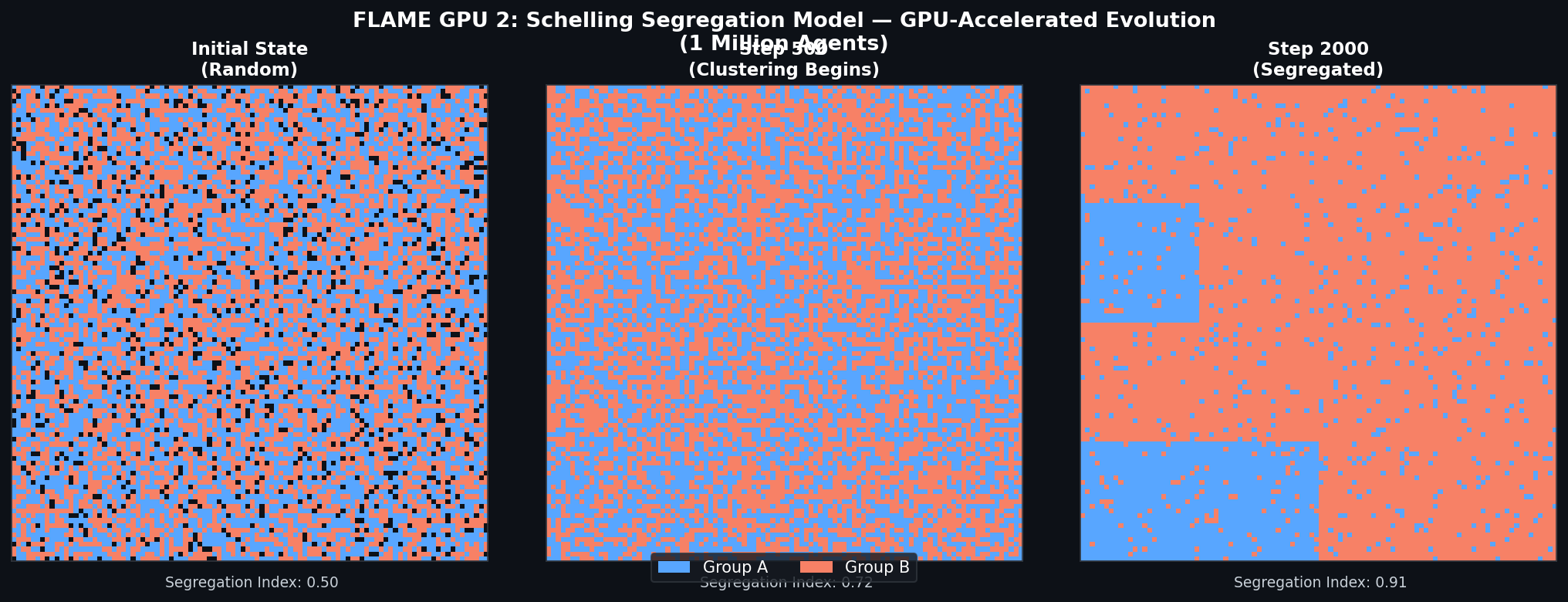
For spatially embedded social systems (residential segregation, pedestrian crowd dynamics, disease spread on a geographic grid), FLAME GPU 2's MessageSpatial2D and MessageSpatial3D types partition the environment into a grid and allow each agent to query only agents within a specified interaction radius. This reduces the naive O(N²) neighbor search to O(N) on average, making million-agent spatial models tractable.
Performance Benchmarks
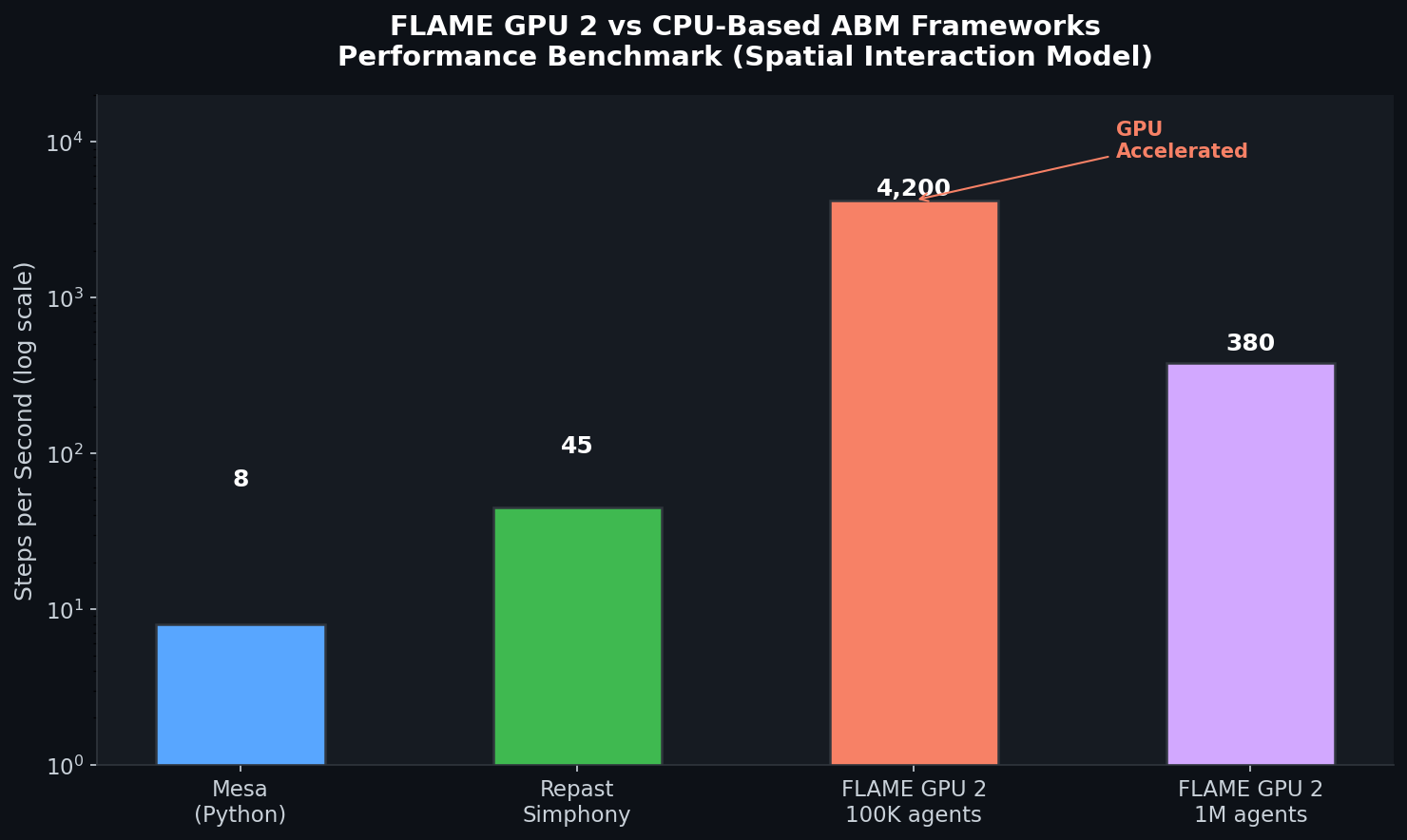
The FLAME GPU 2 development team has published benchmarks comparing their framework against Mesa (Python) and Repast Simphony (Java) on a Boids flocking model (a proxy for spatial social interaction):
| Framework | Agents | Steps/sec |
|---|---|---|
| Mesa (Python) | 100,000 | ~8 |
| Repast Simphony | 100,000 | ~45 |
| FLAME GPU 2 (RTX 3090) | 100,000 | ~4,200 |
| FLAME GPU 2 (RTX 3090) | 1,000,000 | ~380 |
These figures illustrate the architectural advantage: for population-scale social simulations where statistical robustness demands large N, GPU acceleration is not a luxury — it is a necessity.
Practical Workflow for Social System Modelers
1. Model Definition (C++ Header)
Define agents, messages, and agent functions in a C++ model description. FLAME GPU 2's fluent API keeps this readable even for non-CUDA specialists.
2. Simulation Runner
Instantiate a CUDASimulation, load initial agent populations from CSV or programmatically, set run parameters, and call simulate(). The framework handles kernel launch configuration automatically.
3. Ensemble and Parameter Sweeps
The RunPlanVector API lets you define a grid of parameter combinations. FLAME GPU 2 will execute each run sequentially (or concurrently on multi-GPU systems), collecting per-run output logs — ideal for sensitivity analysis on social model parameters like network density, opinion thresholds, or agent heterogeneity.
4. Output and Visualization
Agent state can be logged at configurable intervals to JSON or CSV. For visualization, outputs integrate with standard Python analysis stacks (pandas, matplotlib, seaborn) or network visualization tools like Gephi.
When to Choose FLAME GPU 2
FLAME GPU 2 is the right tool when:
- Population size exceeds ~50,000 agents and runtime is a bottleneck.
- Parameter sweeps over social model parameters require hundreds or thousands of independent runs.
- Spatial interaction is central to the model (segregation, epidemic spread, pedestrian dynamics).
- Your team is comfortable with C++ and has access to an NVIDIA GPU (consumer or data-center grade).
It is less suitable for rapid prototyping of novel behavioral rules (where NetLogo or Mesa's interactivity is preferable) or for models with highly irregular, data-dependent control flow that does not parallelize well.
Getting Started
FLAME GPU 2 is available on GitHub at github.com/FLAMEGPU/FLAMEGPU2 under the MIT license. The repository includes a comprehensive set of example models — Schelling segregation, SIR epidemic, Boids flocking — that serve as practical starting templates for social-system modelers. Detailed documentation is hosted at docs.flamegpu.com, covering installation (CMake-based, with conda environment support), the full API reference, and performance tuning guides.
For teams running large-scale social simulations where CPU frameworks have become the bottleneck, FLAME GPU 2 represents a mature, well-documented path to GPU-scale agent-based modeling without requiring deep CUDA expertise.