
Cadence Xcelium Parallel Simulator: Leveraging Multi-Core Simulation for Large-Scale UVM Testbenches
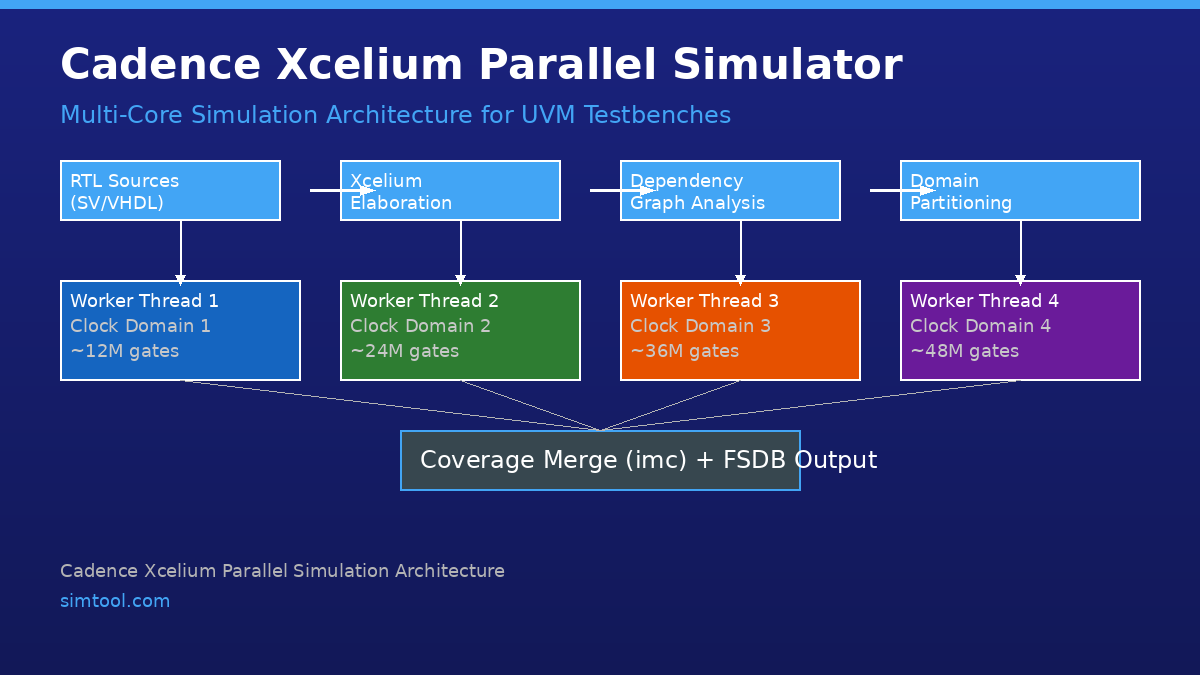
Overview
As SoC complexity continues to grow — with designs routinely exceeding 100 million gates and UVM testbenches comprising thousands of concurrent threads — simulation throughput has become a first-order design constraint. Cadence Xcelium Parallel Simulator addresses this challenge directly by distributing SystemVerilog, VHDL, and mixed-language simulation workloads across multiple CPU cores using a proprietary parallel execution engine. Unlike traditional single-threaded simulators that serialize all event processing, Xcelium's Parallel Simulation (xrun -parallel) mode partitions the design hierarchy into independently schedulable domains, enabling near-linear throughput scaling on modern multi-core workstations and compute farm nodes.
This article examines the practical mechanics of Xcelium's parallel simulation engine, its integration with UVM testbenches, and the configuration strategies that yield the greatest wall-clock time reductions for verification teams targeting functional coverage closure.
How Xcelium Parallel Simulation Works
Xcelium's parallel engine is built on a static partitioning model. During elaboration, the tool analyzes the design's signal dependency graph and identifies clusters of logic that can advance simulation time independently — that is, clusters with no combinational paths between them within a given time step. These clusters are assigned to worker threads that execute concurrently on separate CPU cores.
Key architectural components include:
- Parallel Elaboration: The
xrun -parallel_elaborateflag enables multi-threaded compilation and elaboration, reducing the pre-simulation setup time for large designs by 30–50% on 8-core hosts. - Domain Partitioning: Xcelium automatically identifies clock domains and assigns each domain's logic to a dedicated simulation thread. Designs with multiple independent clock domains (common in multi-die chiplets and heterogeneous SoCs) benefit most from this approach.
- Speculative Execution: For tightly coupled domains, Xcelium uses speculative advancement — threads optimistically advance time and roll back only when a cross-domain event invalidates a speculative result. This reduces synchronization overhead compared to conservative barrier-based approaches.
- UVM Thread Awareness: The parallel engine is UVM-aware, meaning it correctly handles
uvm_componentphase barriers anduvm_tlmFIFO synchronization without requiring testbench modifications.
Practical Configuration for UVM Testbenches
Basic Parallel Invocation
The simplest way to enable parallel simulation is via the -parallel flag to xrun:
xrun -sv -uvm \
-parallel \
-parallel_num_cores 8 \
-top tb_top \
-f filelist.f \
-coverage all \
-log sim.logThe -parallel_num_cores argument should be set to the number of physical cores available on the host, not the hyperthreaded logical core count. Hyperthreading provides minimal benefit for simulation workloads due to the memory-bandwidth-intensive nature of event-driven simulation.
Partition Hints for Tightly Coupled Designs
When automatic partitioning yields poor parallelism (detectable via the xrun -parallel_report output), engineers can provide explicit partition hints using the xcelium.d/xrun.parallel_hints file:
# Force CPU subsystem and GPU subsystem into separate domains
partition cpu_subsystem_tb.dut.cpu_core[*]
partition gpu_subsystem_tb.dut.gpu_cluster[*]This is particularly effective for designs where the automatic dependency analysis is overly conservative due to shared bus interfaces.
Coverage Collection in Parallel Mode
Functional coverage collection is fully supported in parallel mode. Xcelium merges per-thread coverage databases at the end of simulation using the imc (Integrated Metrics Center) tool:
# Merge parallel coverage databases
imc -exec merge_parallel_cov.tcl -work xcelium.d/coverageThe merged database is compatible with Cadence vManager for regression-level coverage tracking and waiver management.
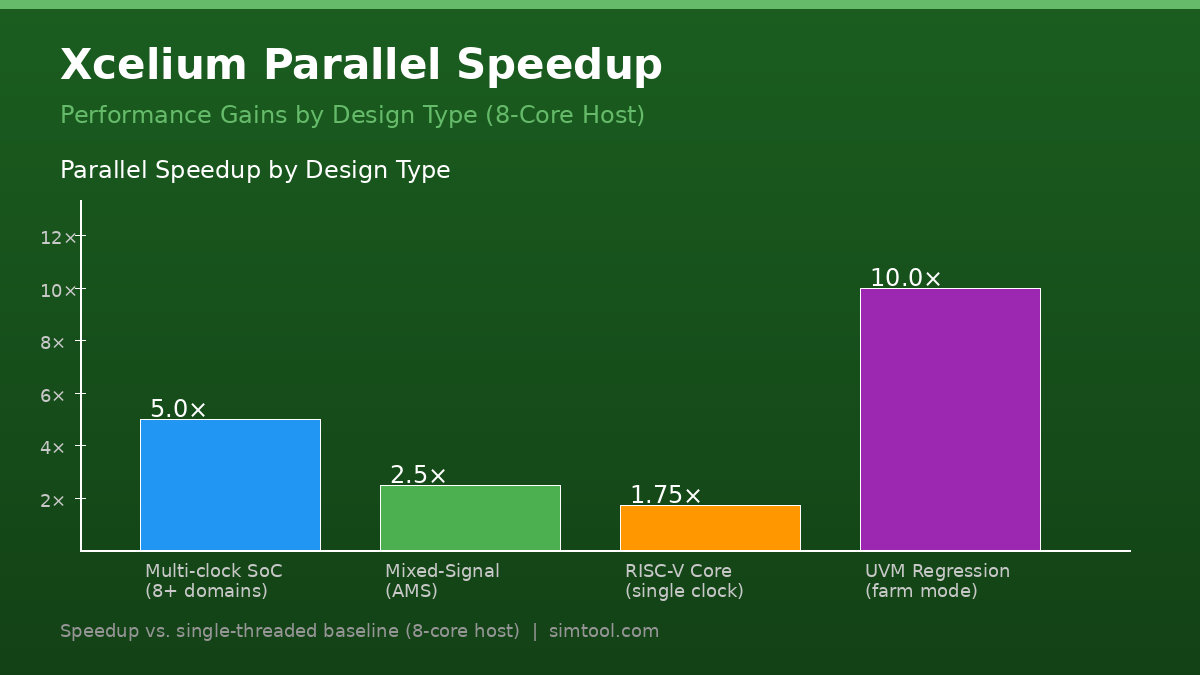
Performance Benchmarks and Realistic Expectations
Xcelium's parallel speedup is highly design-dependent. Based on published Cadence benchmarks and practitioner reports:
| Design Type | Cores Used | Typical Speedup |
|---|---|---|
| Multi-clock SoC (8+ domains) | 8 | 4–6× |
| Single-clock RISC-V core | 8 | 1.5–2× |
| Mixed-signal (AMS) design | 4 | 2–3× |
| Large UVM regression (100 tests) | 16 | 8–12× (farm mode) |
The most significant gains come from regression parallelism — running multiple independent test cases simultaneously across a compute farm using Cadence's Xcelium ML integration with LSF or Grid Engine. In this mode, each test occupies a single core, and the farm scheduler maximizes utilization across hundreds of nodes.
Integration with Cadence Jasper Formal and SimVision
Xcelium integrates natively with Cadence Jasper Gold for formal property verification. Engineers can use the xrun -jg_integration flag to automatically extract formal properties from SystemVerilog Assertions (SVA) embedded in the RTL and pass them to Jasper for exhaustive proof — a workflow that complements simulation-based coverage closure by eliminating corner cases that random stimulus rarely reaches.
For waveform debugging, Xcelium generates FSDB (Fast Signal Database) files compatible with Cadence SimVision and Synopsys Verdi. The -access +rwc flag enables full read/write/connectivity access for post-simulation waveform inspection:
xrun -sv -uvm -parallel -parallel_num_cores 8 \
-access +rwc \
-fsdb \
-top tb_top -f filelist.f
Best Practices for Maximum Throughput
- Profile before partitioning: Run
xrun -parallel -parallel_reporton a short simulation to identify the actual parallelism available in your design before investing in manual partition hints. - Separate compile and simulate steps: Use
xrun -compileandxrun -simulateseparately in regression flows to avoid recompilation overhead across test runs. - Pin memory-intensive tests to NUMA nodes: On multi-socket servers, use
numactl --cpunodebind=0 --membind=0to prevent cross-socket memory latency from degrading simulation throughput. - Use
-timescaleconsistently: Mixed timescale designs force additional synchronization overhead in parallel mode; standardizing on a single timescale across all IPs reduces inter-domain synchronization events. - Leverage Xcelium ML for AI-driven test selection: Cadence's machine-learning extension can predict which tests are most likely to hit uncovered functional coverage bins, reducing the total number of simulations needed for closure.
Further Resources
- Cadence Xcelium Parallel Simulator Product Page
- Cadence Xcelium User Guide (CDNLive) (requires Cadence support login)
- UVM Reference Implementation (Accellera)
- Cadence vManager Coverage Management
- IEEE 1800-2023 SystemVerilog Standard
Cadence Xcelium's parallel simulation engine represents a meaningful step forward for verification teams constrained by simulation throughput rather than stimulus quality. By understanding the partitioning model, configuring the tool appropriately for the design's clock domain structure, and integrating parallel simulation into a farm-based regression flow, teams can achieve the coverage closure rates needed to meet aggressive tape-out schedules without proportionally scaling compute infrastructure.